Published on
Last Updated on
Estimated Reading Time: 7 min
Dynamic Programming is one of those techniques that every programmer should have in their toolbox. But, it is also confusing for a lot of people.
For a long time, I struggled to grasp how to apply Dynamic Programming to problems. Most articles that I could find on the internet gave the final dynamic programming solution without actually showing the approach taken to arrive at the final solution.
This article will show the benefits of using a Dynamic Programming approach to solving problems with an example. In the end, I will show some steps you can use to find a Dynamic Programming solution.
Hopefully, after reading this article, you will find Dynamic Programming intuitive and straightforward.
What is Dynamic Programming?
Dynamic programming is an efficient method for solving specific types of complicated computational problems. These problems are generally those that can be broken down into smaller overlapping sub-problems. It can be characterised basically as recursion along with memoization.
Memoization is the ability to save the results of specific states to reuse later.
Profiling
To prove that we are improving our solution, we need statistics that we can compare. I will be using google benchmark to help profile our solutions. The benchmark will look like this.
-----------------------------------------------------------------
Benchmark Name Running Time Iterations/sec Items/sec
-----------------------------------------------------------------
- Benchmark Name: The name of the benchmark. It will be in the format the FunctionName/value is passed in.
- Running Time: The time it took for our function to return a result.
- Iterations/sec: The number of times the function could be invoked in 1 second.
- Items/sec: The number of items that were processed in 1 second.
While 2 and 3 will indicate the time complexity of the function, 4 will provide us with the space complexity.
Example: Fibonacci Series
The classic example to explain dynamic programming is the Fibonacci computation which can be formalised as follows
Fibonacci(n) = 0; if n = 0
Fibonacci(n) = 1; if n = 1
Fibonacci(n) = Fibonacci(n-1) + Fibonacci(n-2) ; if n >=2
Naive Recursive Approach
The Fibonacci sequence can easily be solved by the following recursive method:
long Fibonacci(long n)
{
if (n == 0)
{
return 0;
}
if (n == 1)
{
return 1;
}
return Fibonacci(n - 2) + Fibonacci(n - 1);
}
On running the above code and profiling it on my machine, I get:
-----------------------------------------------------------------------------
Benchmark Name Running Time Iterations/sec Items/sec
-----------------------------------------------------------------------------
FibonacciRecursive/10 0 ms 2488889 17.0685M
FibonacciRecursive/20 0 ms 21333 303.026k
FibonacciRecursive/30 8 ms 179 3.60887k
FibonacciRecursive/40 997 ms 1 40
FibonacciRecursive/50 124510 ms 1 0.40282
Although this method returns almost instantly for n <= 30, it takes a little less than a second for n = 40 and approximately 2 minutes for n = 50. Why is the amount of running time increasing so rapidly? This can be explained easily by following the execution stack. Let's do this for n = 6 to keep it simple. The following image shows the sequence of calls that are made.
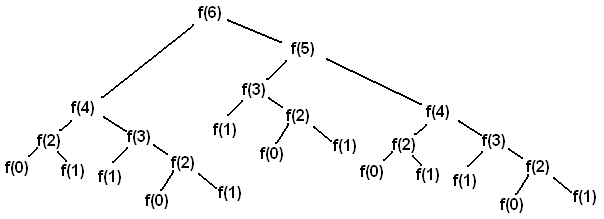
Looking at the image, we can see that to calculate fibonacci(6), we calculate
- fibonacci(5) 1 time
- fibonacci(4) 2 times,
- fibonacci(3) 3 times,
- fibonacci(2) 5 times,
- fibonacci(1) 8 times; and
- fibonacci(0) 5 times.
Throughout the call-stack, we are repeatedly computing values that we have already computed. This amount of duplicated work being done keeps on increasing as n becomes larger.
You must have realised that this solution is not at all scalable. If you are thinking that there has to be a better way, you are correct.
Top-Down Recursive approach with Memoization
The 1st step to improving the above solution is to add memoization, i.e. to store the previously computed values in a data structure. Although you can use any data structure that you like, I will use a map for the purposes of this example.
#define MOD 1000000007
long FibonacciMemonized(long n)
{
std::map<long, long> computedValues;
computedValues.insert(make_pair(0, 1));
computedValues.insert(make_pair(1, 1));
return FibonacciMemonized(n, computedValues);
}
long FibonacciMemonized(long n, std::map<long, long>& computedValues)
{
if (computedValues.find(n) != computedValues.end())
{
return computedValues[n];
}
long newValue = (FibonacciMemonized(n - 1, computedValues) + FibonacciMemonized(n - 2, computedValues)) % MOD;
computedValues.insert(make_pair(n, newValue));
return newValue;
}
The top method is our main method. It adds the 2 base cases to a map and then calls the bottom method with the map as one of the arguments.
This bottom method is our recursive method. In this method, we check if the map contains the computed value. If it does, we just return that value. Otherwise, we calculate the value for n-1 and n-2.
We mod the result using 1000000007 to avoid overflows. Before returning their sum, we store the value in our map.
How better is this version? Let's look at the benchmark results.
-----------------------------------------------------------------------------
Benchmark Name Running Time Iterations/sec Items/sec
-----------------------------------------------------------------------------
FibonacciMemonized/1000 0 ms 4073 3.60284M
FibonacciMemonized/5000 2 ms 896 2.90891M
FibonacciMemonized/10000 3 ms 407 2.82288M
FibonacciMemonized/15000 5 ms 242 2.66937M
FibonacciMemonized/20000 7 ms 187 2.65432M
We can see that we have reduced the amount of time drastically. Even for n = 20000, the result is instantaneous.
However, there is a problem with this approach. Can you spot it?
If you said memory usage, you are absolutely correct. Although the new version is much faster, it is still a recursive algorithm.
And, the problem with recursive algorithms is that each recursive call takes some space on the stack. A high enough n, and we run the risk of running out of memory.
Let's see why this happens with an example where n = 100. Because we don't have the result when we start, we call the method recursively for 999, 998, 997 ... 1. At that point, we have all the computed results in our map.
As we return from our recursive functions, we just look up the value in the table and return it. So, even though we have reduced the number of recursive calls, we still make n recursive calls before getting our initial result. This can easily be seen by comparing the iteration/seconds between this and the previous algorithm.
Let's try something better.
Bottom-Up Approach with Dynamic Programming
In the previous approach, our main problem was the recursive nature of our algorithm. Let's see if we can get rid of it by using an iterative approach.
How do we do this? Instead of starting from the final value, we will begin with the smallest value of n and build up the results.
#define MOD 1000000007
long FibonacciDP(long n)
{
if (n == 0)
{
return 0;
}
if (n == 1)
{
return 1;
}
long* results = new long[n + 1];
results[0] = 0;
results[1] = 1;
for (int i = 2; i <= n; i++)
{
results[i] = (results[i - 1] + results[i - 2]) % MOD;
}
long value = results[n];
delete[] results;
return value;
}
In the above function, we have an array of n+1 to store the results. We initialise the array for our base cases of n=0 and n=1 and then iterate from 2 to n. At each step, we can use the 2 previously computed values and finally return the result.
Let's again look at the benchmark results to see how does this approach do?
-----------------------------------------------------------------------------
Benchmark Name Running Time Iterations/sec Items/sec
-----------------------------------------------------------------------------
FibonacciDP/100000 1 ms 1906 130.711M
FibonacciDP/600000 5 ms 280 111.456M
FibonacciDP/1100000 10 ms 145 110.626M
FibonacciDP/1600000 14 ms 100 112.249M
FibonacciDP/2100000 18 ms 81 110.448M
Even when n=210,000, this approach returns almost instantly. At the same time, since this algorithm is not recursive in nature, we have drastically reduced the required amount of space. We can see this by comparing the items/sec, which decreases much slower even though n is increasing more rapidly than before.
You may be thinking that since we have a linear time and space complexity, this is the end.
In most cases, that would be true. But, in this case, we can optimise our solution further.
Bottom-Up Approach with Dynamic Programming (Optimised)
In the last algorithm, the amount of space required is proportional to n. This is because we are storing all the results. But, we don't need to keep all of them.
Let's eliminate the array by using just 3 variables - 2 to store the previous results and 1 to store the current result.
#define MOD 1000000007
long FibonacciDPOptimized(long n)
{
if (n == 0)
{
return 0;
}
if (n == 1)
{
return 1;
}
long n1 = 0;
long n2 = 1;
long current = 0;
for (int i = 2; i <= n; i++)
{
current = (n1 + n2) % MOD;
n1 = n2;
n2 = current;
}
return current;
}
Although this algorithm is doing precisely the same thing as the previous one, we have reduced our space complexity to be constant since the amount of space needed is no longer dependent on n.
Again the benchmark results for comparison.
----------------------------------------------------------------------------------
Benchmark Name Running Time Iterations/sec Items/sec
----------------------------------------------------------------------------------
FibonacciDPOptimized/100000 0 ms 2987 202.569M
FibonacciDPOptimized/600000 3 ms 498 207.242M
FibonacciDPOptimized/1100000 5 ms 280 202.138M
FibonacciDPOptimized/1600000 7 ms 187 205.188M
FibonacciDPOptimized/2100000 10 ms 128 205.0708M
Here, we can see that although n is increasing, the items/sec is more or less the same.
This is the best we can do, and no further optimisations are possible.
Conclusion
From the above example, we can see that we only need to identify overlapping subproblems and then avoid duplicated work by caching the computed results.
To recap, we can use these steps to find a dynamic programming approach to our problem.
- Find the overlapping subproblem.
- Start with a recursive solution
- Modify the recursive solution to use a top-down memoized version.
- Remove the recursion by making it an iterative solution.
- If you don't need to keep all the previous results, keep only the required ones.
If you would like to run the code yourself, you can find the code here.
Hopefully, this article has removed the mystery around Dynamic Programming.
In the following few articles in the series, we will look at some of the more common problems that can be solved by Dynamic Programming and use the above steps to come up with a solution.
Have you tried Dynamic Programming before? How was your experience? Let me know.